AI-gateway
Summary
The AI-gateway is a standalone-service that will give access to AI features to all users of GitLab, no matter which instance they are using: self-managed, dedicated or GitLab.com.
Initially, all AI-gateway deployments will be managed by GitLab (the organization), and GitLab.com and all GitLab self-managed instances will use the same gateway. However, in the future we could also deploy regional gateways, or even customer-specific gateways if the need arises.
The AI-Gateway is an API-Gateway that handles traffic steered to it from a
globally reachable cloud.gitlab.com/ai/* route. IDEs currently use cloud.gitlab.com/ai/*
indirectly through a GitLab Rails instance. In
future we plan to allow network endpoints such as IDEs to connect directly to
cloud.gitlab.com (for more information, see directly connected clients).
The AI-Gateway then directs this traffic to other services, in this case
AI-providers and their models. This north/south traffic pattern allows us to
control what requests go where and to translate the content of the redirected
request where needed.
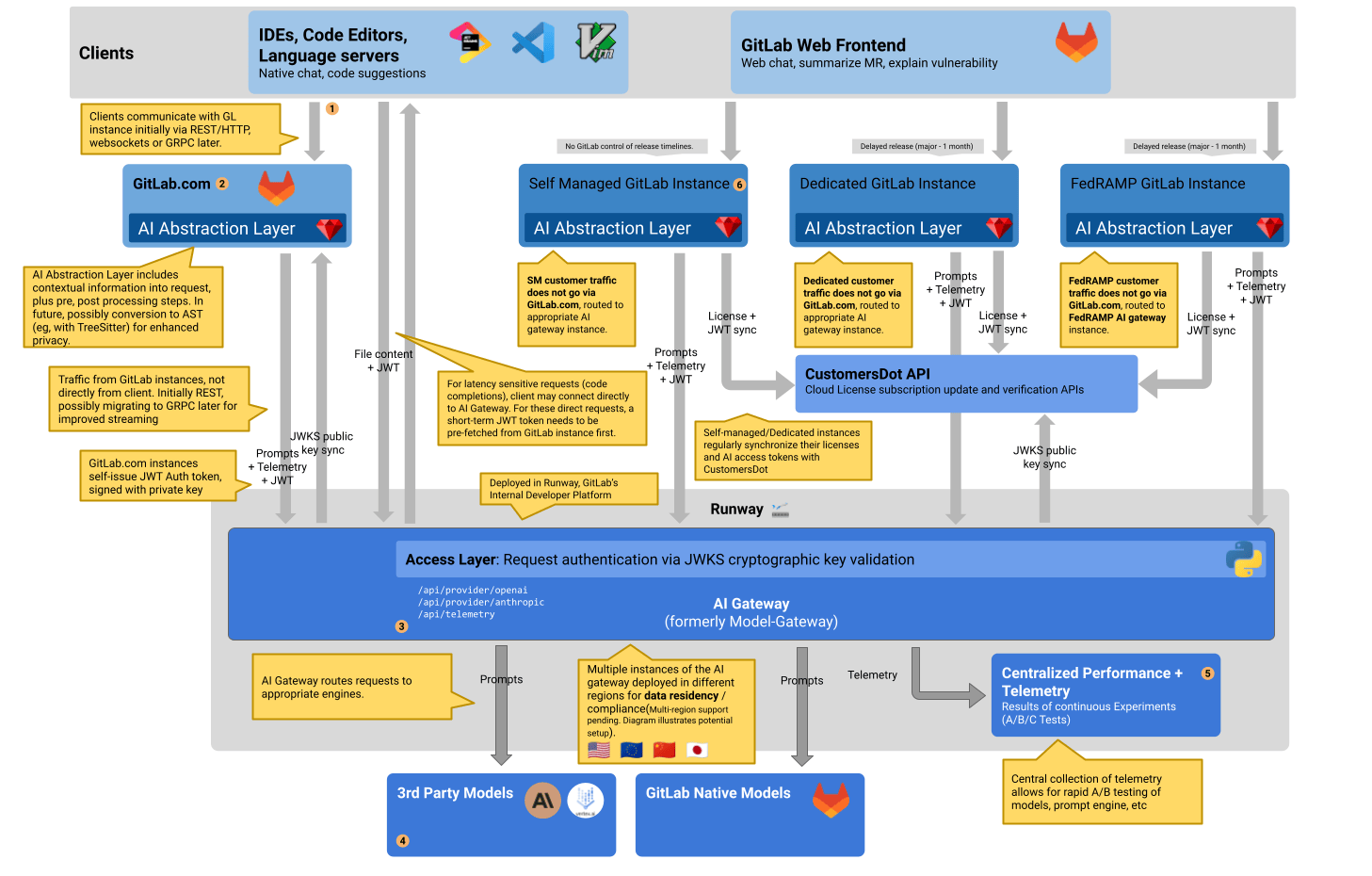
Currently, multi-region deployment is not supported; it's a feature under consideration. The existing diagram illustrates a potential architecture for deploying across multiple regions.
By using a hosted service under the control of GitLab we can ensure that we provide all GitLab instances with AI features in a scalable way. It is easier to scale this small stateless service, than scaling GitLab Rails with its dependencies (database, Redis).
It allows users of self-managed installations to have access to features using AI without them having to host their own models or connect to 3rd party providers.
Language: Python
The AI-Gateway was originally started as the "model-gateway" that handled requests from IDEs to provide Code Suggestions. It was written in Python.
Python is an object oriented language that is familiar enough for Rubyists to pick up through in the younger codebase that is the AI-gateway. It also makes it easy for data- and ML-engineers that already have Python experience to contribute.
Directly connected clients
Direct connections are not supported yet and this work is tracked in this epic.
Decision: ADR-001: Allow direct connections
Code completion requests will be sent directly from a client to AI Gateway to improve latency of these requests. It will be up to the client to decide if a request can be sent directly to AI Gateway or to GitLab Rails for additional enrichment. Usage of direct connections will be optional and backward compatible. If a client will not support detection of completion requests, it can still send these requests through GitLab Rails (as is now) without specifying the type of code suggestion request.
API
Basic stable API for the AI-gateway
Because the API of the AI-gateway will be consumed by a wide variety of clients, it is important that we design a stable, yet flexible API.
To do this, we can implement an API-endpoint per use-case we build. This means that the interface between client and the AI-gateway is one that we build and own. This ensures future scalability, composability and security.
The API is not versioned, but is backward compatible. See cross version compatibility for details. The AI-gateway will support the last 2 major versions. For example when working on GitLab 17.2, we would support both GitLab 17 and GitLab 16.
Because clients can connect directly to AI Gateway, common functionality like rate-limiting, circuit-breakers and secret redaction should be added both at this level of the stack as well as in GitLab Rails.
Protocol
The communication between the AI-Gateway service and its clients (including the GitLab Rails application) shall use a JSON-based API.
The AI-Gateway API shall expose single-purpose endpoints responsible for providing access to different AI features. A later section of this document provides detailed guidelines for building specific endpoints.
The AI Gateway communication protocol shall only expect a rudimentary envelope that wraps all feature-specific dynamic information. The proposed architecture of the protocol allows the API endpoints to be version agnostic, and the AI-Gateway APIs compatible with multiple versions of GitLab(or other clients that use the gateway).
This means that all clients regardless of their versions use the same set of AI-Gateway API feature endpoints. The AI-gateway feature endpoints have to support different client versions, instead of creating multiple feature endpoints per different supported client versions.
We can however add a version to the path in case we do want to evolve a certain endpoint. It's not expected that we'll need to do this often, but having a version in the path keeps the option open. The benefit of this is that individual GitLab milestone releases will continue pointing to the endpoint version it was tested against at the time of release, while allowing us to iterate quickly by introducing new endpoint versions.
We also considered gRPC as a protocol for communication between GitLab instances, JSON API, and gRPC differ on these items:
| gRPC | REST + JSON |
|---|---|
| + Strict protocol definition that is easier to evolve versionless | - No strict schema, so the implementation needs to take good care of supporting multiple versions |
| + A new Ruby-gRPC server for vscode: likely faster because we can limit dependencies to load (modular monolith) | - Existing Grape API for vscode: meaning slow boot time and unneeded resources loaded |
| + Bi-directional streaming | - Straight forward way to stream requests and responses (could still be added) |
| - A new Python-gRPC server: we don't have experience running gRPC-Python servers | + Existing Python fastapi server, already running for Code Suggestions to extend |
| - Hard to pass on unknown messages from vscode through GitLab to ai-gateway | + Easier support for newer VS Code + newer AI-gateway, through old GitLab instance |
| - Unknown support for gRPC in other clients (vscode, jetbrains, other editors) | + Support in all external clients |
| - Possible protocol mismatch (VSCode --REST--> Rails --gRPC--> AI gateway) | + Same protocol across the stack |
Discussion: Because we chose REST+JSON in this iteration to port features that already partially exist does not mean we need to exclude new features using gRPC or Websockets. For example: Chat features might be better served by streaming requests and responses. Since we are suggesting an endpoint per use-case, different features could also opt for different protocols, as long as we keep cross-version compatibility in mind.
Single purpose endpoints
For features using AI, we prefer building a single purpose endpoint with a stable API over the provider API we expose as a direct proxy.
Some features will have specific endpoints, while others can share endpoints. For example, Code Suggestions or chat could have their own endpoint, while several features that summarize issues or merge requests could use the same endpoint but make the distinction on what information is provided in the payload.
Our goal is to minimize code that we can't update on a customer's behalf, which means avoiding hard-coding AI-related logic in the GitLab monolith codebase:
- We want to minimize the time required for customers to adopt our latest features, and
- We want to retain the flexibility to make changes in our product without breaking support for a long-tail of older instances.
- We want to be able to serve all GitLab distributions (.com SaaS, Self-managed, and Dedicated) with minimal complexity.
- We want to isolate AI capabilities to reduce risk and have a unified control plane.
- We want to provide a unified implementation that can support our "best-in-class" multi-model ensemble approach allowing us to easily support many AI models and AI vendors.
- We want a single point for controlling and measuring cost.
- As much as possible, we want to track metrics (usage statistics, failures to respond, usage pattern, question categories, etc.) in the gateway rather than distributed across many points. (Of course some metrics can only be captured on the client side.)
Having the business logic in GitLab Rails requires customers to upgrade their GitLab instances, which affects the first point. Some of the on-premises users cannot upgrade their instances immediately due to their company policy. For example, if we had a bug in a prompt template in GitLab Rails and fixed it in 16.6, and customers are using 16.5 and the next upgrade is scheduled in 3 months, they have to use the buggy feature for 3 months.
This does not mean that prompts need to be built inside the AI-gateway. But if prompts are part of the payload to a single purpose endpoint, the payload needs to specify which model they were built for along with other metadata about the prompts. By doing this, we can gracefully degrade or otherwise try to support the request if one of the prompt payloads is no longer supported by the AI gateway. It allows us to potentially avoid breaking features in older GitLab installations as the AI landscape changes.
The AI-Gateway API protocol
It is important to build each single-purpose endpoint, in a version-agnostic way so it can be used by different GitLab instances and by external clients. To achieve this goal:
The AI-Gateway protocol shall rely on a simple JSON envelope wrapping all feature-specific information. The AI-Gateway protocol can be seen as a transport layer protocol from the OSI model (eg: TCP, UDP) which defines how to transport information between nodes, without being aware of what information is being transported.
The AI-Gateway protocol does not specify which information received by single-purpose endpoint should be processed and in which way. Providing endpoint with the freedom to decide if they will use data coming from each protocol envelope or ignore it.
The AI-Gateway protocol defines each request in the following way:
- Each single-purpose endpoint shall accept requests containing a single JSON object with a single key:
prompt_components. - The
prompt_componentskey shall contain an array of JSON envelopes that are built according to the following rules:
Each JSON envelope contains 3 elements:
-
type: A string identifier specifying a type of information that is being presented in the envelopespayload. The AI-gateway single-purpose endpoint may ignore any types it does not know about. -
payload: The actual information that can be used by the AI-Gateway single-purpose endpoint to send requests to 3rd party AI services providers. The data inside thepayloadelement can differ depending on thetype, and the version of the client providing thepayload. This means that the AI-Gateway single-purpose endpoint must consider the structure and the type of data present inside thepayloadoptional, and gracefully handle missing or malformed information. -
metadata: This field contains information about a client that built thisprompt_componentsenvelope. Information from themetadatafield may, or may not be used by GitLab for telemetry. The same as with thepayloadall fields inside themetadatashall be considered optional.
The only envelope field that is expected to likely change often is the
payload one. There we need to make sure that all fields are
optional and avoid renaming, removing, or repurposing fields.
To document and validate the content of payload we can specify their
format using JSON-schema.
An example request according to the AI-Gateway component looks as follows:
{
"prompt_components": [
{
"type": "prompt",
"metadata": {
"source": "GitLab EE",
"version": "16.7.0-pre",
},
"payload": {
"content": "...",
"params": {
"temperature": 0.2,
"maxOutputTokens": 1024
},
"model": "code-gecko",
"provider": "vertex-ai"
}
},
{
"type": "editor_content",
"metadata": {
"source": "vscode",
"version": "1.1.1"
},
"payload": {
"filename": "application.rb",
"before_cursor": "require 'active_record/railtie'",
"after_cursor": "\nrequire 'action_controller/railtie'",
"open_files": [
{
"filename": "app/controllers/application_controller.rb",
"content": "class ApplicationController < ActionController::Base..."
}
]
}
}
]
}Another example use case includes 2 versions of a prompt passed in the prompt_components payload. Where each version is tailored for different 3rd party AI model provider:
{
prompt_components: [
{
"type": "prompt",
"metadata": {
"source": "GitLab EE",
"version": "16.7.0-pre",
},
"payload": {
"content": "You can fetch information about a resource called an issue...",
"params": {
"temperature": 0.2,
"maxOutputTokens": 1024
},
"model": "text-bison",
"provider": "vertex-ai"
}
},
{
"type": "prompt",
"metadata": {
"source": "GitLab EE",
"version": "16.7.0-pre",
},
"payload": {
"content": "System: You can fetch information about a resource called an issue...\n\nHuman:",
"params": {
"temperature": 0.2,
},
"model": "claude-2",
"provider": "anthropic"
}
}
]
}Cross-version compatibility
When renaming, removing, or repurposing fields inside payload is needed, a single-purpose endpoint that uses the affected envelope type must build support for the old versions of
a field in the gateway, and keep them around for at least 2 major
versions of GitLab.
A good practice that might help support backward compatibility: provide building blocks for the prompt inside the prompt_components, rather then a complete prompt. By moving responsibility of compiling the prompt out of building blocks and into the AI-Gateway, more flexible prompt adjustments are possible in the future.
Example feature: Code Suggestions
For example, a rough Code Suggestions service could look like this:
POST /v3/code/completions{
"prompt_components": [
{
"type": "prompt",
"metadata": {
"source": "GitLab EE",
"version": "16.7.0-pre",
},
"payload": {
"content": "...",
"params": {
"temperature": 0.2,
"maxOutputTokens": 1024
},
"model": "code-gecko",
"provider": "vertex-ai"
}
},
{
"type": "editor_content",
"metadata": {
"source": "vscode",
"version": "1.1.1"
},
"payload": {
"filename": "application.rb",
"before_cursor": "require 'active_record/railtie'",
"after_cursor": "\nrequire 'action_controller/railtie'",
"open_files": [
{
"filename": "app/controllers/application_controller.rb",
"content": "class ApplicationController < ActionController::Base..."
}
]
}
}
]
}A response could look like this:
{
"response": "require 'something/else'",
"metadata": {
"identifier": "deadbeef",
"model": "code-gecko",
"timestamp": 1688118443
}
}The metadata field contains information that could be used in a
telemetry endpoint on the AI-gateway where we could count
suggestion-acceptance rates among other things.
The way we will receive telemetry for Code Suggestions is being discussed in #415745. We will try to come up with an architecture for all AI-related features.
Exposing AI providers
A lot of AI functionality has already been built into GitLab Rails that currently builds prompts and submits this directly to different AI providers. At the time of writing, GitLab has API-clients for the following providers:
To make these features available to self-managed instances, we should provide endpoints for each of these that GitLab.com, self-managed or dedicated installations can use to give these customers to these features.
In a first iteration we could build endpoints that proxy the request to the AI provider. This should make it easier to migrate to routing these requests through the AI-Gateway. As an example, the endpoint for Anthropic could look like this:
POST /internal/proxy/anthropic/(*endpoint)The *endpoint means that the client specifies what is going to be
called, for example /v1/complete. The request body is entirely
forwarded to the AI provider. The AI-gateway makes sure the request is
correctly authenticated.
Having the proxy in between GitLab and the AI provider means that we still have control over what goes through to the AI provider and if the need arises, we can manipulate or reroute the request to a different provider. Doing this means that we could keep supporting the features of older GitLab installations even if the provider's API changes or we decide not to work with a certain provider anymore.
I think there is value in moving features that use API providers directly to a feature-specific purpose built API. Doing this means that we can improve these features as AI providers evolve by changing the AI-gateway that is under our control. Customers using self-managed or dedicated installations could then start getting better AI-supported features without having to upgrade their GitLab instance.
Features that are currently experimental can use these generic APIs, but we should aim to convert to a single purpose API endpoint before we make the feature generally available for self-managed installations. This makes it easier for us to support features long-term even if the landscape of AI providers change.
API in GitLab instances
This is the API that external clients can consume on their local GitLab instance. For example VSCode that talks to a self-managed instance.
These versions could also widely defer: it could be that the VSCode extension is kept up-to-date by developers. But the GitLab instance they use for work is kept a minor version behind. So the same requirements in terms of stability and flexibility apply for the clients as for the AI gateway.
In a first iteration we could consider keeping the current REST payloads that the VSCode extension and the Web-IDE send, but direct it to the appropriate GitLab installation. GitLab Rails can wrap the payload in an envelope for the AI-gateway without having to interpret it.
When we do this then the GitLab-instance that receives the request
from the extension doesn't need to understand it to enrich it and pass
it on to the AI-Gateway. GitLab can add information to the
prompt_components and pass everything that was already there
straight through to the AI-gateway.
If a request is initiated from another client (for example VSCode), GitLab Rails needs to forward the entire payload in addition to any other enhancements and prompts. This is required so we can potentially support changes from a newer version of the client, traveling through an outdated GitLab installation to a recent AI-gateway.
Discussion: This first iteration is also using a REST+JSON approach. This is how the VSCode extension is currently communicating with the model gateway. This means that it's a smaller iteration to go from that, to wrapping that existing payload into an envelope. With the added advantage of cross version compatibility. But it does not mean that future iterations also need to use REST+JSON. As each feature would have it's own endpoint, the protocol could also be different.
Authentication & Authorization
GitLab provides the first layer of authorization: It authenticates the user and checks if the license allows using the feature the user is trying to use. This can be done using the authentication, policy and license checks that are already built into GitLab.
Authenticating the GitLab-instance on the AI-gateway was discussed in:
The specific mechanism by which trust is delegated between end-users, GitLab instances, and the AI-gateway is covered in the Cloud Connector access control documentation.
AI Gateway is accessed only through Cloud connector which handles instance authentication (among others). Cloud connector will need to support also end-user authentication because some requests (e.g. code completion) will be sent directly by clients instead of sending all requests indirectly through GitLab Rails. A possible solution in which short-term user tokens are used is described in Epic 13252. AI Gateway needs to be able to distinguish between requests proxied by GitLab Rails and direct client requests because some endpoints or parameters may not be available for direct requests (for example clients should not be able to send final prompt, but rather only sub-components from which the final prompt is built by AI Gateway).
Embeddings
NOTE: For the embedding database, see RAG for GitLab Duo.
Embeddings can be requested for all features in a single endpoint, for example through a request like this:
POST /internal/embeddings{
"content": "The lazy fox and the jumping dog",
"content_type": "issue_title",
"metadata": {
"source": "GitLab EE",
"version": "16.3"
}
}The content_type and properties content could in the future be
used to create embeddings from different models based on what is
appropriate.
The response will include the embedding vector besides the used provider and model. For example:
{
"response": [0.2, -1, ...],
"metadata": {
"identifier": "8badf00d",
"model": "text-embedding-ada-002",
"provider": "open_ai",
}
}When storing the embedding, we should make sure we include the model and provider data. When embeddings are used to generate a prompt, we could include that metadata in the payload so we can judge the quality of the embedding.
Deployment
Currently, the model-gateway that will become the AI-gateway is being
deployed using from the project repository in
gitlab-org/modelops/applied-ml/code-suggestions/ai-assist.
It is deployed to a Kubernetes cluster in it's own project. There is a staging environment that is currently used directly by engineers for testing.
In the future, this will be deployed using Runway. At that time, there will be a production and staging deployment. The staging deployment can be used for automated QA-runs that will have the potential to stop a deployment from reaching production.
Further testing strategy is being discussed in &10563.
Alternative solutions
Alternative solutions were discussed in applied-ml/code-suggestions/ai-assist#161.
Decisions
Future work
AI Gateway aim is to become the primary method for the monolith to access machine learning models across all usages of GitLab and create a consistent user journey when developing AI-backed features. To do so, these goal is split down into three categories:
- Centralized Access Through AI Gateway
- Self Managed AI Gateway
- Unit Primitives
Centralized Access Through AI Gateway
The AI Gateway, a standalone service, is the sole access point for all communication between GitLab installations and third-party AI models. It is designed to centralize and manage access to all GitLab features, whether they are in-app functionalities or code suggestions, irrespective of their deployment methods.
This strategy significantly simplifies enterprise management and abstracts machine learning away from the monolith. With future expansions including telemetry, embeddings API, and multi-region/customer-specific deployments, our goal is to provide a scalable, comprehensive AI solution for all GitLab users, regardless of their installation type.
Model registry is a feature that allows users to use GitLab to manage the machine learning models. While not solely focused on large language models, and currently more targeted at smaller model applications, which could be deployed in various ways: as a standalone library, a service, a pod, a cloud deployment, and so forth. For these user-deployed models, the ability to auto-configure an API that's accessible through the AI Gateway could be a significant feature.
Unit Primitives
Unit Primitives are a fundamental part of our strategy for managing access to AI features through the AI Gateway. They represent the smallest unit of functionality that can be accessed and managed through the Gateway. This approach provides a more granular control over the functionalities exposed through the AI Gateway and simplifies the management of AI features. It also paves the way for future work on supporting user-deployed models and locally hosted models. From a business perspective, unit primitives are the smallest pieces that may be shuffled across various tiers or packaging models, providing flexibility and adaptability in our offerings.
In the initial iteration, we will support two primitives: Code Suggestions and Chat. The latter will encompass all Chat features in one primitive.
In the next iteration, we plan to decompose the Chat primitive into multiple primitives based on top-level tools. This work is dependent on the completion of the task to move classification into the AI Gateway.
The introduction of Unit Primitives will simplify the management of AI features and provide a more granular control over the functionalities exposed through the AI Gateway. This will also pave the way for future work on supporting user-deployed models and locally hosted models.
For more details, refer to the Initial Set of Unit Primitives issue.
Self Managed AI Gateway
Self-managed instances can either use GitLab-hosted AI Gateway or have their own AI Gateway if they want to use self-deployed models, with Runway likely being the deployment method. This means part of our work will be to ensure that the AI Gateway can be deployed in a self-managed environment. This work will go hand-in-hand with the work to support locally hosted models (local inference) in support of GitLab AI features.
Other components in the AI stack
While AI Gateway centralizes access to AI features and models, it interacts with other components to help users achieve their goals:
- AI Agents: create and manage agents and prompts
- Model registry: manage and deployment machine learning models
Model registry
Model registry is a feature that allows users to use GitLab to manage the machine learning models. While not solely focused on large language models, and currently more targeted at smaller model applications, which could be deployed in various ways: as a standalone library, a service, a pod, a cloud deployment, and so forth. For these user-deployed models, the ability to auto-configure an API that's accessible through the AI Gateway could be a significant feature.
AI Agents
AI Agents is a feature that allows users to implement and manage their own chats and AI features, managing prompts, models and tools. Development is currently in its early stages. Once mature, we intend to move GitLab feature to agents, but there are blockers that currently prevent us from doing so:
- Lack of prompt templating.
- Implement replication of user-defined prompts into ai-gateway.
- Implement replication of GitLab-defined prompts into self-managed installations (e.g., organization-level agents where we prepopulate with a few agents).